什么是HashMap
基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。 此实现假定哈希函数将元素适当地分布在各桶之间,可为基本操作(get 和 put)提供稳定的性能。迭代 collection 视图所需的时间与 HashMap 实例的“容量”(桶的数量)及其大小(键-值映射关系数)成比例。所以,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。
数据结构
HashMap 的底层是基于数组加链表结构。
HashMap 可以看做是有很多桶bucket,每个桶只存放一个元素Entry。这就构成了一个Entry数组。
bucket的元素类型是Map.Entry(Map.Entry是interface,HashMap.Node类实现了该接口)。Entey对象包含:hash、key、value、next(下一个对象的引用地址)。
因此可能出现的情况是:HashMap 的 bucket 中只有一个 Entry,但这个 Entry 指向另一个 Entry ——这就形成了一个 Entry 链。
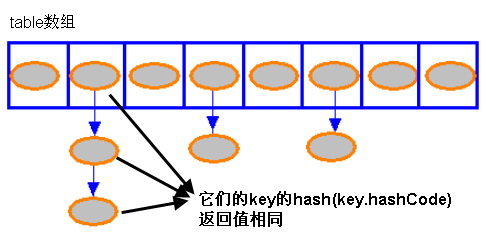
实现原理
对于 HashMap 及其子类而言,它们采用 Hash 算法来决定集合中元素的存储位置。当系统开始初始化 HashMap 时,系统会创建一个长度为 capacity 的 Entry 数组,这个数组里可以存储元素的位置被称为bucket。每个 bucket 都有其指定索引(根据key的hash值生成),所以 HashMap 可以根据 key 的哈希值,定位到该 key 所在的桶在桶数组中的位置,从而达到快速访问的目的。
当存在不同的 key 的 hash 值一样,也就是发生了哈希冲突。第一个 key 的 Entry 对象的 next,指向第二个元素的 Entery 对象,此时也就构成了链表。通过循环该链表,根据 key 的 equals 值比较,找到 key 所对象的 Entry 对象。最早放入的 Entey, 在链表的最末端。
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 根据hash计算得到索引值,从数组中获取Node链表的第一个元素,如果key的值相等,就直接返回
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// key对应的Node节点并不在链表的第一个位置上
if ((e = first.next) != null) {
// HashMap 遍历TreeNode,得到key对象的Node
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// LinkedhashMap 遍历Node,得到key对象的Node
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
阅读 HashMap#get 方法的源码可知:
- HashMap 的每个 bucket 里只有一个 Entry 时,HashMap 可以根据索引、快速地取出该 bucket 里的 Entry。
- 在发生“Hash 冲突”的情况下,单个 bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。